Creating Reusable Datasets in Azure Data Factory with Parameters
Joel Cochran
Data, ETL, Azure, ADF
April 20, 2021
Creating Reusable Datasets in Azure Data Factory with Parameters
Serverless ETL with Azure Data Factory
One of the biggest challenges we face working in big data environments is moving and structuring data. It has been said that as much as 80% of a data professional’s time is spent doing Extract-Transform-Load (ETL), leaving only 20% of their time to do the important work of Analytics and Insights. Modern tools such as Azure Data Factory (ADF) seek to flip those percentages so that data professionals can spend more time providing value.
Here at Causeway Solutions, we have been leveraging ADF for several years, and have succeeded in lowering the time spent performing ETL even farther. According to Microsoft, ADF is a “fully managed, serverless data integration solution for ingesting, preparing, and transforming all your data at scale."
In this article, we will focus on a simple strategy you can use to improve the reusability of your ADF Pipelines that focus on data movement.
A Quick Dataset Overview
Datasets are the primary means of describing data for both sources and sinks. Dataset properties are defined by their underlying type of connected Linked Service. For instance, an Azure SQL Dataset will include properties such as Schema and Table, while a Blob Storage Dataset will include properties such as Container, Directory, and File.
Most Datasets also have the ability to define a Schema. This is great if you need to access the columns during processing or if you want to enforce a particular schema. In those cases, Datasets tend to be highly focused or tied to a specific data source (like a SQL Table or CSV file). In many scenarios, however, like moving data from an SFTP site to Blob Storage, a schema is not necessary for the given ETL operation. Whether you need a schema or not, parameterizing a Dataset will make it reusable across a variety of activities and scenarios. Reusable Datasets will limit the number of ADF resources you need to manage and help simplify your overall solution.
Adding Parameters to a Dataset
The most efficient means of moving data files in their natural state is binary transfer, so ADF includes a Binary Dataset type. Binary does not have a schema and does no data transformation or translation, so it is ideal for moving files from one place to another, even if the service types are completely different.
Start by creating a Binary Dataset and connecting it to a Blob Storage Linked Service:
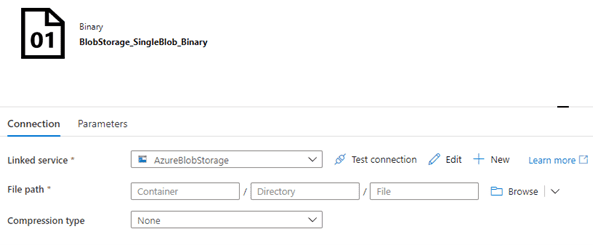
Next, open the Parameters tab and add the necessary parameter variables:
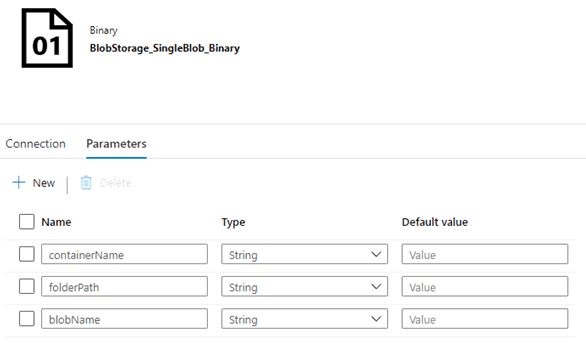
Next, switch back to the Connection tab. If you click inside one of the File path boxes, you’ll expose the “Add dynamic content” option:
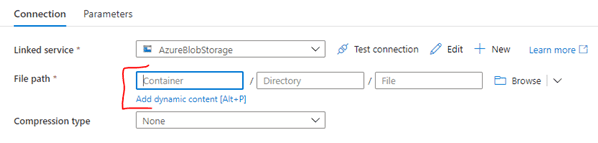
Click on the “Add dynamic content” link to open the editor. Under the “Parameters” section, select the related item:
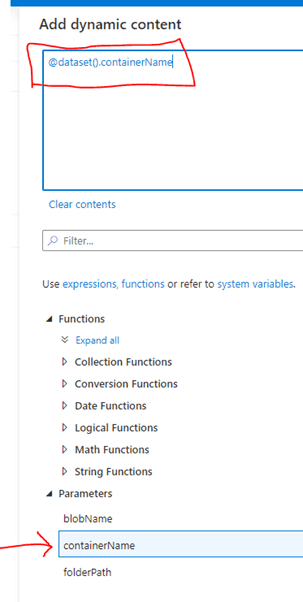
Click on the “Finish” button to return to the Dataset editor, and the parameter reference will appear in the box:
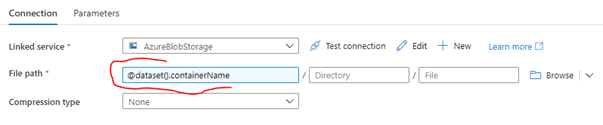
Repeat this to reference the rest of the parameters:

NOTE: while this example parameterizes every value, it is certainly not required. For instance, if you are working against a known container, you could hardcode the container value while parameterizing the directory. You could also just reference the container and directory to create a folder-level Dataset.
Using the Dataset
To demonstrate this, we’ll build the ADF version of “Hello World” - copying a blob from one Blob Storage container/directory to another container/directory in the same account using Copy Activity. Another great use case is downloading files from an SFTP server to Blob Storage. In our version, thanks to parameters, we will be able to use the same Dataset for both the Source and the Sink.
- Create a pipeline with a Copy activity:
' width='569' height='566' xlink:href='data:image/png%3bbase64%2ciVBORw0KGgoAAAANSUhEUgAAAEAAAABACAYAAACqaXHeAAAACXBIWXMAAA7DAAAOwwHHb6hkAAAKUUlEQVR42uVaya/rVhnPH8EgVUKig9jRDRuQYI2E2LLqkgU7KCwqsUAsKAVeuyhCqrqpCiuESp9oKaqqN9x3x5fceUhyE9txBjuzHSdO4ozOj%2b8c27lJbm6mm9yXp2fpp3NyfHx8vu98s%2bPDqq5eb/zv0fFnfPmcPfU4vL69LNB6tqbD1nX0XOJ768iAq0Na8uaaDUCWgUSc%2bs0%2bE9ZaAsxGC1rNglFvwLAaKFGr1512btA6JUGCLsbQ7nZXw%2bRlMcB2N/bLzxS89EcRL/9FxLf%2bJOIVal%2b7J%2bGVe87Yq9R/9Z44BRK%2b/Wc2n%2ba%2bJ%2bPld0Wcpmt8/a695gx4458pvPZuAj/9exo/%2blDB9/6Wwk8%2bTuPHH6nwvSXA92YEvl/PiN%2b47Zsh%2bJPVPgPWSQquMeAX91V8820ZP/wwhe9/kMJ33ovju%2b8n8Pr7Sbz0joyv/yGGb7w9D9gzAg6VNWeA09o4JFF9qnZxQPATdpUO9gi7ShuBdAf7DBm3HcBBhqE7BDbvKGtjM2Gh3HBeaK%2brDeCbs21ENQvssDZyFvazFvJ1IGkCaWoVFym6r1Kbtqi1nD6bM4pExWnj1L7173cQVIMuE%2bz1ZECXGBArtbAt1/C1X32Cn392gROtA1HvIiDmcRQv4VDWEM43sS8VsHuZxl4kw/tCyYZkAKLRG4JUBiJ6D3999A/Ei/L6M0DQGjjNtvGD338J3xsf42cf7KJA4vvwSMR/t47x6UM/toNJfPk0iPvU/8/GAbYuEkR8DzEi1mu9Pjv983wLVgdrR/xYFQiRzDORPko38Ppvv8Dv7odBB85PWCwxBnV4ywiUKy5MDBHPWg%2bMAReFNvJVC6Mxx1oy4LJokeiS/hJRRCvUmiPWg4QyJGq4RuyQBFQwxIBirfl8MCBcsDih56rJdVtyCQ6RUWRgfYFswr6YQ7TY5ozhRHtwmRChe/GyYwjPOQNa6x0J9hlAKpAiaf3f9jE%2b%2btfnSJE6RIot7IYVbF/EOYEX6So%2bfbCHJ6cSZ8Ag4XFiXjBTx1f7EXwSKSBKY6HniQEXuRri5OY2z2V8QUaP9ZnOnyQNDm7V6XR3Qin4oxl%2bTxq1%2bnR/P6bhMNvgjDnLtcgGNNebAd6%2b0uU6ZL2GRKmOpGEhPtBPlt3f1Gdjcb3qtsS0kgt3vlJpQnHnSVoVtVZnfRlwfWO9GTFhbm903voRPyYU7vWlYbh/WwwXXNaKAVeEvpjw4QW/XhgJ6Ha76HQ61yWADTK0222OVqvV7zN49wfnXN2jRdnC7rz%2buN0dO/%2bmdTtj3js4Z9I6E9d1n%2bUhfiiEnZ0d1Go1zgxv7nQVmGC0eg0LnWr12ni7VF6KsVtojTmf8XkvkSUBl5cRiIKAqBhDTJJwGY70nZih64gnEsgV8sjnM1DVNKplIpQ4yeYoKRlxWUIikUS77lQ/ygalzqFTSMkUVEUlKEipKWSyGX4qvAhrlpFMJiAIEiQphnQmTWunYDXcCkq3hWQmhxTNUdIZmOUS1HSa1slAURWaq0IUJb5GsaiNeLMZjKDHgLwSR/DkAHIkRJsOIimEEBOifU5VqyZiMdokEZnOqLRZEUbF7N/PqknaRBxyLAG7/0wFKVnACYnf2ckZJNpoiuadnBzx1NupnDcgRonphFRKpXcIODwMoG65DOh1OeHCZRiCnICeVyEnk5ATCs6D5/ygkkmFDi9Eh6DOLQU%2bpg890tlszcno5DLF8wQW4qpVx3gweCc2JG005t0fFNdxY70R0fbmdN1y%2bajo2/217SGCxu3jpnVngc95gY1spQWx2KQw2EFMa0Itt/hJOZuxxy5g9%2b8Pj3lE2PbVnEEMiuG4%2b4NzRsdumt%2b17TmId57xjZ7OMi62MLOwnuvx4Lz4%2bviysIjR7NuAZrNJLs3hIqvcdl33NK9R4caPjGPZMGAQTNMk11NFhcYMPubcY%2bPMrlTNJYA8kVmpwKB3lKod6HVCtY1aswuz0UGJflfqTmvU2khpDbS79jADwsFjPPhqA3t7T%2bHf20OWDE%2b3OVDFmdFtMTCCa0Rciix/JCKS4csiS5Y8EiYDS54lnS2uJKpjjD9O1PBYNLEnVJDIWxCydQRiJo5kE8dKHWmjwcdbnREGtNstGCV2MlXO1XZn/m95/e%2bLZgUVOhFd05Amd5nN5VEqlchNFTjK5Qrq9RqhvjRwKTDNqXtkhJuNKwPtm0TkvBlcv7pMOt5sNq6iO2qdvoMWSVaD3N%2bywY3kBJUd/SgzFAdM0%2btZmfGs091J9IyOj60HjLqomxgx6eVsDSYBzLDeJbwYYZ5D6EsAcyO3jc29%2b0z/WdLh6GftDuDYgKprA%2bZkgMO187MjPNncxP5%2bgELRY%2bztbGLj8UME/H4cHR7xrG9WCWAMeBaX996FJKBOJ6ZTwqPrGvcEGYr3meXmPp2stm335mLAXef7TPzNRRiwiJWflQHzBlGLwrM7t5KAWV80jwTc9WUuYgNW4YKY2kzyJssWfc50emexWLy9BMziQ6cxoEYWmUkBO5G7APMA2Wx2GTbgeup5Xf97M9mIianoCjLBRWKAIQloNVtjJ3ibHf2ENs0GGG42yESTnQxTi4rbLl0CCBV33YVVQI3HEAjsYnt7D9u7fuwfHOH8/AI5ygrTmax77tNVgIGJZMOqQ1EzEEQBoigiIki8ZhgMi2sYBxA6LBs0dORyBeTzBa5TLA5otdoUZrbmsgHeKbNsMJfLucgTsjwzXH6U6ESCt3ODSyhRD/pklv11Ou0B3b%2bqCLXc7HDZWCgXuOmB23iBRsPip9KwLO4R2ImvEnXeVnlCtLAExOMyZDkGicBLSyUdhQG/Oo8E8PIUPa/pBmz3K8wqwYw0kwCmegszQJQEHBwe4PTsBNFoFCWy4BrlBvMygJfEqiZtxkCpbOKuLvbeyrJygVH/P2tY7P22SPR5MdQtVrIS2WphcuIb7teklSVD04ziIGO87wPzfqi4DRb5E8ZQWZzpE2vZmFfHc6IspscdXuVh3O7eYG293ywAYqVvll7fRUjMAiEnbV/ABniu4%2bAwgI2Nx9jc3kLkMgQhdIKHjx5hY3MXoVAQjze2oKSSUJTUUFwwvixe4x8xTymQanbu7q%2bxt4oDmM9mrsuiCI5xlUkD02UWYDBJqFad7%2brc306xAbwkrmsoFor9ELhSKa8QTui98oLIrDbAS4buqiBymz9h%2bZz5vTEbxsDfS%2bx%2bhMcsu2U1ptoAlpuzWOIuS%2bW3MoJCJIQnjzdIb0PwP91BOBRC9PICgf0A2YJt%2bHd3cXIWhqqkkad4fhID8nkn3s/nc2svBX0GWHVWFC31rSkPYXmCUeYEa5pONsKaKQ5gtoRJQc39%2b8w6/kFypTaAuU4mAe2Br8tr/Tc5dulakU46B71koFDI81BWK%2bQoLc6jQOmxRtJRKDjtTeGx91sj/WeeZJEa3TNjQDwmYGtzC%2bfBMA72/YhGLiFdnuHRg0d4uueHEEtw1TCMylQJYIxibnDQBjy/KjDF3d30dZjF5YOltLWXgElfUOextJMSq3W8/g/uHGoDsi/nbgAAAABJRU5ErkJggg==' /%3e%3c/svg%3e)
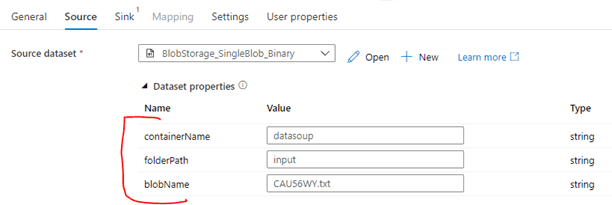
- On the Source tab, select the Dataset you created above. Selecting a Dataset that has parameters defined will display the Dataset properties section:
' width='612' height='205' xlink:href='data:image/png%3bbase64%2ciVBORw0KGgoAAAANSUhEUgAAAEAAAAAVCAYAAAD2KuiaAAAACXBIWXMAAA7DAAAOwwHHb6hkAAAFZUlEQVRYw71YaZfaOBCc//%2bf8naz%2b2FnN5mDe8BcPrgM2Fy28VmpljHLBMKYSSZ%2br5%2bNkCyp1F1d7bssy3B2XWpTzf%2b3p/sAWYl%2br9rx9iVjTy1N07O2X2l3MuloZKE/6MMyTHSHBlL%2bEfg7aC8tWPoQ/V4Xvh%2boBRqGgV5/iP1uyxeksO0plsslHNfB0lki2O9Vv5FloKN1MBia0Ac6EtlIGsM0hxjqBqYzm/NZGA74e6hj0O9hu/OuAvgRlwJgtXJhz20sFgvYC0cBEIYRNH2MnjGBRtv5%2bcZc9p0vlogT2VCKHYGQ8evNhrY%2bArUiIHO%2bT/qaBFYASNMEjsO2%2bYJgETDeJ%2bMJ2/hOe3Yc%2b9Gn/soDkiQ5QyVlmx8m6Lu0Vcp7Ci%2bUDSdnrnrJhROCc6k9Td86WRmbXLU4Tt7sc4vdlYjKi/EdhiGCIFC2p9vL75D3iJ6TxLH6Le1RFOX/0aKTtugw3vd91Sb3mON%2b96UAGPT7aLXa6Ha70IcDVCoV1OpNVGt1bDfbi67jeR6en58xJn8MdR2a1mbMa9BNA%2b12m7wyhk7%2b0Loami8vaL%2b0YVoWBoMBOUWDZY0JRKy8bcPwmUwmBGWPgJ5mLvZwGDrS5riuWuhiG2NP4MbWhJzjKqKO6FHLXYTZOoTjxZjyLr/nmxBbP75IqhdJ0PN2jOMV1us1dtst7yu4jEvXXSk%2bOL7oxAMCnthsNmUfR5GgbduM7bniEcsyMZ1O%2bTzHeDwi4c1yfrFznlnM874Cou975JEd3%2bMiS2KMlnus/AT2ZIZatQ5rMlZJabKOFAC9bp/Eqqt1RAy17jxAd%2bZjvArR4X1I8AQQL4hLEepdGcb9vs%2bvYunTk7iSfUsm0PLp%2bCwE3nKTS4uNopAeYPP0F%2bpUHWep3FU8yVk6tCVm9ILVaq1OV5hdNvL9e36U/3MrsgFOdMGP15leWfelOY4AlITzFap7hoBpjqgLhmg26nihZmh3NHQ6bVTJIRqfm/UaOcFSMZ4DgA/xpPd6w5EDbgEABy6QK0nzVFJ2G6Ib/EPWKFLl78r3csUxeYTzS7a53QNONi8bYa7Dl/t/8c8ff%2bLp8RER83MhXS8JmVxfcMx/9/j892cYzAK/ywuKOTyKtr8%2bfcLD10cUkuT2ECBjZ/f3yJjqmDuBXq%2bUpi9iWQF0Jm7id1tZ1ViEoPJYeT5NgzcBQGJjkleeIOLGY1HkM41KWpS0FjCticBJs/TMA0LmeSHJhdQOlMKrA2l6BFXG3mqSPrdM2ygTAjQBTK2Ray6AKw/AAcGMQibj4uXqUvjU6g1UH76iUq2iWauiXn1AvVGloInOWFhiXzRDq90hWXagGzpFlKnqiiJ0bjE5TalFyobAmtqm8lTHQ6WKuePeGAIFAOLyIlre7P56sUq4UMgIABsKLhFb8rwQ8fROs1lAyXsuzfdq7sP9%2b3pH0uztAFA24yBPe5TOjVpDnWar0WTq610VTuIB4vYm5bJ5kMI/U/OnqhrdlfaAHdNxq0nv4x52nv9OD%2bDgIgTWjF/R60oG23MV1/mE6ZmgKQooEUgmpfJoPFbxKy4s8lueNyyny9tGnb48X57zfH5Jgcu5A4t1ynqz/YkQ4EYVCbJ%2bF7eW/CqmGPZKHhYAhPSUufINwFbfBoQU5fuAnKYCpJQJAW5yEiypJ8RjZA3FJ4D3kaBhIGNxI1fjsYGvlWc0Wg18qT6hwYowzc6V17GAkhOgdNa6PVaePVaQXfT6A1VBSkjIAsumPym5Y4K/pSccy4XsI0mwSINEkPUyMqY9rkCKgtykPQh%2bTERZ/rFD6v7T7wj7w3MQ%2bLenQnqBjD8VYNdIsACi0B7y%2bxswwIU4qMCObQAAAABJRU5ErkJggg==' /%3e%3c/svg%3e)
- The values for the Dataset properties can be hardcoded, parameters, variables, or expressions. In this case, I’ve just hardcoded the values for this operation. Now repeat these steps for the Sink:
' width='611' height='225' xlink:href='data:image/png%3bbase64%2ciVBORw0KGgoAAAANSUhEUgAAAEAAAAAYCAYAAABKtPtEAAAACXBIWXMAAA7DAAAOwwHHb6hkAAAGHUlEQVRYw91Y6XLiRhD2G/jN9gX29fIjD5D8S3b/pLayXmyLy0aABAJzSBy6L4TmS/dw2MYCC8qbqkRVXaMZzdU9/X3doyshBF49VH/TJptftxf1Ker3Xv9j43%2byiO1a4qrf09But6FpXWh9A6t1jjSJ0e10MBgMqF1HGEZyc1r7ETXlHr7nyrppmZhOp5jNZjBnFhx3076Yz1Ct1aD3NaitNubzhWy3zBE6nRbG4wkGtBav0WaR6%2bsoZ6IPeXZLiavA9%2bHSxqV4PtbrNbIsk3XHcWSZrlbI8xzqyEala8L2YxqaI45j%2bDSeJQhDBEEgLczttm3DD3wykEklt4MMGcJ2bNnfdVwsFguqO/A8j9Zy5dq8zr8gYldeHZpm1%2bnQLbnNSwWWpPs6Fy%2bMeGDafF34TRzMWTw2p7k367Mxigxy2LZ%2bOeYjDPByM8fwbPkZbp8iNKYJ6iQNM0WdhMumtZKyay%2bWFWqThCSWooxjPJrJWRAQHwUBtdXC/Z2CTusBt7cVKITdWr2OlHAvDkhpc/JAZ5mj1tIw0LtYWFPCchudtorR0wD9no7RcICZOaH3HroaYZzWMIw%2bppMx%2brqOIb3HUbTfS%2bguUX0KEGcCC2%2bFuZfQeEvySpIkxEsC8yCT0LGoPdiOTYmv5v4KMxInymRphxmNTxEk61Ok%2bkyCKS0Qx5FciDHKWGYMFzF6vn0fOBm%2baUvcGzZt3MMdlXeGA2Xo4oc%2bx99tU9Z/6At812by/X5A9d6CShcVKmujAI9Wigc6%2bcYkkp4QpWv0TC5XUB9UKNUq/NAnAwBTL8PSdvBQb2BCRuAnoP7NcYjONMLYSdE2I2izBFMnQRCvj0afVwY4FY4KQ9j2nafPtuXunQ5wX9%2b38UkR/PlAXgqfdrTK97LzrrIOXyasngjVzwY4FitPxX5BEcB3PdjLBYVAigrLObE6s7srS9deYk7u6xO7B76HVZq8UOQEgR7sId/zEN607cn5Zf93dCiEQHnaeJ4oI4X0bo/yBAP1eg31WpWwrqFFWH94aKJ6r6ClqjK%2bzynURXu8v3akcsZ/v8978xR4w5kG2A3miS%2blXSZRzjHWGZ1UXlqJjxJ5cJTf8B42qm8o/jwP4IInIBbXvnzBt19%2bxffffqdEJ9znEKc2wBHgz69/4FapkiHWZ6XI5%2bK8qI9LUP3r61fc3ikU5TdOcJYHyGSGwqSg9FdQSMrIvVfk%2buIgahQaYItfGdYos/yo0z9vHiLcMECarsQWWmcaYDKh0zdeUZmQ4fF1hiZEsSfIlJkl2KbPlCKzhJcIhWueg8vDxO2Y8m9I8FQmWGiA4RDC2sTgIRFgtXqPauVWJk%2bNehUNpYLK/Q0WS7vQPfleodOlR%2bULkNpGvz/Yp7yX3AMY0xxp3oPC7ptNeYRSqeIHQcBaOBdAgFwfbAQ%2bdVpcWpMtv6VGTqoSihCszC5kPXuF2F56bHh80aLLEl%2b2WAGfQqUvvznyElVGePxyudx7QFmj8bNKU5Gm6QUQoNMXBAF%2b5nTlHRgjjCcjSn2HFBLHb3KGNxAgJaemieHTCCaVljWX9clkSimuKZXhU2WOKCPMJwyDsiExiROMn8aYWJZIVtkFHkBWF8Tk8l%2bAOcVDs4VOV4VOLq2qHTr57GR8ZwMMyVia3iMqMdDT%2bxiQMXq9PgUWg5RhgkpJsVgq955wfsEcUtYA7IFaR0ez%2bSis%2bfJMA%2bxygGbz6NX2OVPLN9DYyjME%2bL%2bDg80/iM2/BoZDKMlw08YwKCOuhMtSjt2H4GMi3lzxxXbMBXkAnTbogqK3e7i5qaDRrEJpNlChG2T0IhwWPazscPgEjW6JnCW22x30jQG63S5dwqJ9snQOCXpbEiyTB/BPl9pdHXdKTcxtd%2b8B%2bbuyiSGcOuTEAzl0PY8p9pFCOZ1A7vle7odBTpundJz/Nbx9uJ3cNafTk0JEJseTAvKdsCy/nyM8hmBwdM3D9Yk38iiMcsd2cuIb1m19dVH69fiI/8vDBjBKiRBSBL/btiEUZSOqaghNM8Rs9tzvyByCx/8EKatDwbg%2bG%2bC6lAhxLbgMQ1nu5fPna3F1dS0%2bfdrUs%2bxacN//iPwD8OgsnOpg70EAAAAASUVORK5CYII=' /%3e%3c/svg%3e)
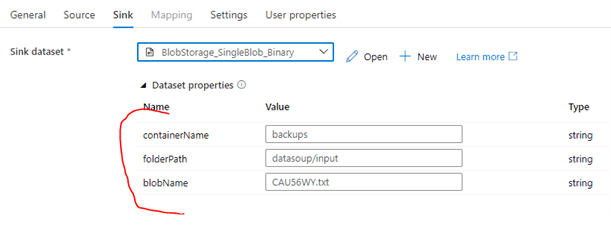
Executing the pipeline will now copy the Blob from one container/directory to a different container/directory.
Wrapping it up
While brief, this introduction should serve to get you started with parameterized Datasets. When combined with pipeline parameters, variables, expressions, and other activities such as Get Metadata, they can go a long way towards making your ADF patterns more robust and reusable. Until next time, Happy Coding!
Ready to learn more? Contact Causeway Solutions to get started!